
Astronomy is rapidly becoming a big data science, and therefore much of my recent work involves machine learning and astrostatistics. These methods have provided insights not just into galaxy evolution, but a wide range of astronomical problems. I have particularly focused on methods for classifying objects, so that additional observations of a small, well-chosen sample allows us to learn about the entire dataset. A main advantage of these methods is that the classification does not come from theoretical models, but rather from the data itself.
Successful applications of these other astrostatistical methods include:
- A method for identifying objects where template fitting has produced a “catastrophically”-wrong redshift, then correcting these to produce more complete catalogs of the early Universe.
- An improved selection of “dead”, or quiescent, galaxies
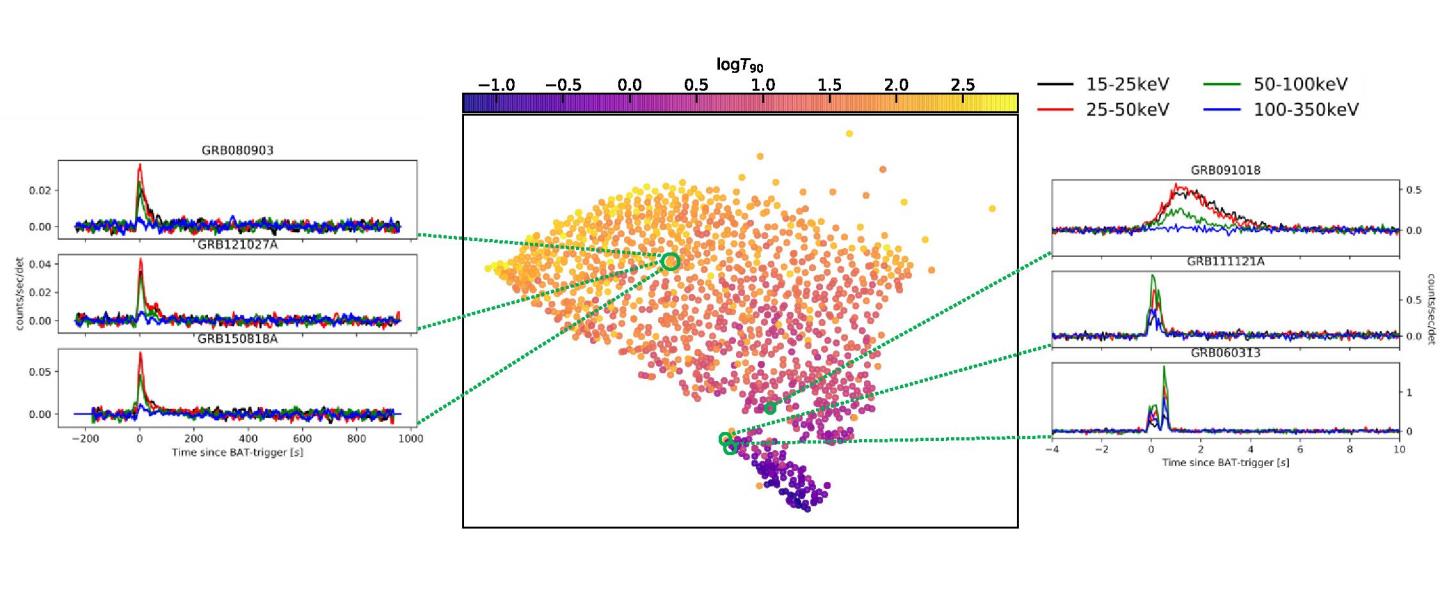
- Classifying gamma-ray bursts into two types from their prompt emission alone, a central problem in the study of these bursts
- A re-analysis of Type Ia supernova data suggesting the possibility of a new disagreement between local and early-Universe measurements of the composition of the Universe in addition to the previously-reported tension between measurements of the Hubble constant.
Key Recent Papers
- Jespersen et al. 2020, “An Unambiguous Separation of Gamma-Ray Bursts into Two Classes from Prompt Emission Alone”
- Steinhardt et al. 2020, “A Method to Distinguish Quiescent and Dusty Star-forming Galaxies with Machine Learning”
- Steinhardt & Jermyn 2018“Nonparametric Methods in Astronomy: Think, Regress, Observe—Pick Any Three”
- Masters et al. 2016, “Mapping the Galaxy Color-Redshift Relation: Optimal Photo-z Calibration Strategies for Cosmology Surveys”